Methodology

The Objective
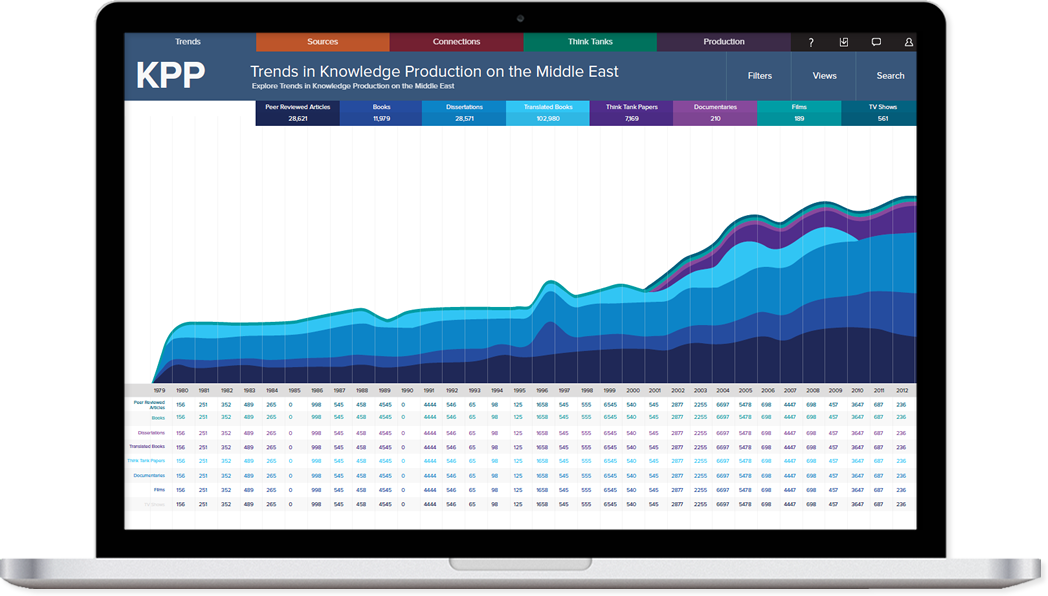
The purpose of the Books Database is to create a list of known books across a variety of publishers that have produced knowledge on the Middle East since 1979. The list will be converted into both a data file compatible with most analytic software as well as a user-friendly interface for in-depth exploration of the list. This database will provide insight into the knowledge production that requires long-term investment (research and writing) and consumed by an elite to general audience. At the time of this report, the database holds 10,502 books on the Middle East from a variety of mainstream, university and alternative publishing houses. These books are from the 348 publishers this project will use as sources.
The Sources
The sources used in the database include publishers from well-known books, open Internet searches, the Books In Print database, existing hubs and sites listing publishers and through academic institutions. In some instances, the team systematically reviewed the Middle East sections of libraries based at the University of Texas and the College of William & Mary. Each publisher is listed along with background information about that publisher. Some websites would contain links to related publishers.
The Logistics
There are two stages in the database development. The first stage includes the data mining for books covering the Middle East and simultaneously expanding the publisher list. Data mining during the first stage occurs by mining the sources for books published within 10-year increments.
Data mining for individual books was performed by examining a publisher’s website, where the books published in the last ten years are often listed, and determining which books on the website warranted inclusion in the database. Efforts were made to examine beyond the Middle East subject section, as we often found not every book relevant to our database could be found under the banner of “Middle East.” Other examples include country searches (i.e., searching for a term like “Syria”), searches related to Islam, and foreign policy searches. Team members mark which publishers and years have been covered on this common list as well as emailing other team members with what data has been entered. In this way, the team was able to keep track of completeness.
After completing data mining for each publisher on the list for a ten year period, a list of tasks was drawn up to spot-check efforts and edit systematic and nonsystematic errors out of our database. Upon the completion of these tasks, the cycle begins again, this time starting with completing data entry for the next set of ten years. During the quality control portion of the cycle, team members go through and complete tasks such as “Fix broken/unreliable/missing links” and “remove duplicate entries.” The page also allows team members to place their mark next to each task when the task is completed.
The second stage of development is the review and coding of each book that will decipher the author’s disciplinary approach, the book’s topic, region and population.
The Formatting
The Books Database currently exists in the form of a three page excel spreadsheet. The first page is devoted to information pertaining to the books collected from data mining pursuits, while the second is devoted to collecting information related to the publishers mined for books. A third page is devoted to listing and keeping track of the completion of tasks related to editing and spot-checking our data-mining efforts.
On the page relating to data entry taken, information is taken for each book mined under a variety of columns. Columns for the Title, Author(s), Editors, Year of Publication, Publisher, ISBN, and Source are listed and given priority when taking data entry. Columns also exist for the Language, number of languages, Institutional type, Degree Level of author, University of author, Country of publication, and Country of Press is also taken; this information is given less priority, and columns such as these exist primarily to further specific research interest of data miners for certain publishers. For most books, this information is not taken.
The second sheet includes a list of publishers and background variables, which include the host institution, the name of the publisher, a link to their website, as well as information on whether the publisher is a private or public institution and what type of ownership governs the organization are all listed (public or private). Also on this page is a system of keeping track of the data that have been mined, and by whom. For each publisher, columns for time periods of five-year intervals starting in 2005-2010 (should we mark this as 2010-15?) and going back to 1979-1984 are listed.
The third page is a list of tasks that are performed to assure the data is formatted correctly and systematic errors are eliminated as a liability.